DeepSeek V3.2技术解析
- 官方文档:https://api-docs.deepseek.com/news/news251201
- 论文:https://huggingface.co/deepseek-ai/DeepSeek-V3.2/resolve/main/assets/paper.pdf
2025 年 12 月 01 日,DeepSeek 发布了 DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。官方网页、App 及 API 均已更新为正式版 DeepSeek-V3.2。其中,Speciale 版本在推理能力上表现更强,可通过 API 调用,价格与 V3.2 相同。
DeepSeek-V3.2 在一般任务上对标 ChatGPT-5 和 Gemini Pro 3.0。图 -1 展示了 Speciale 版本在数学和推理能力上的表现。
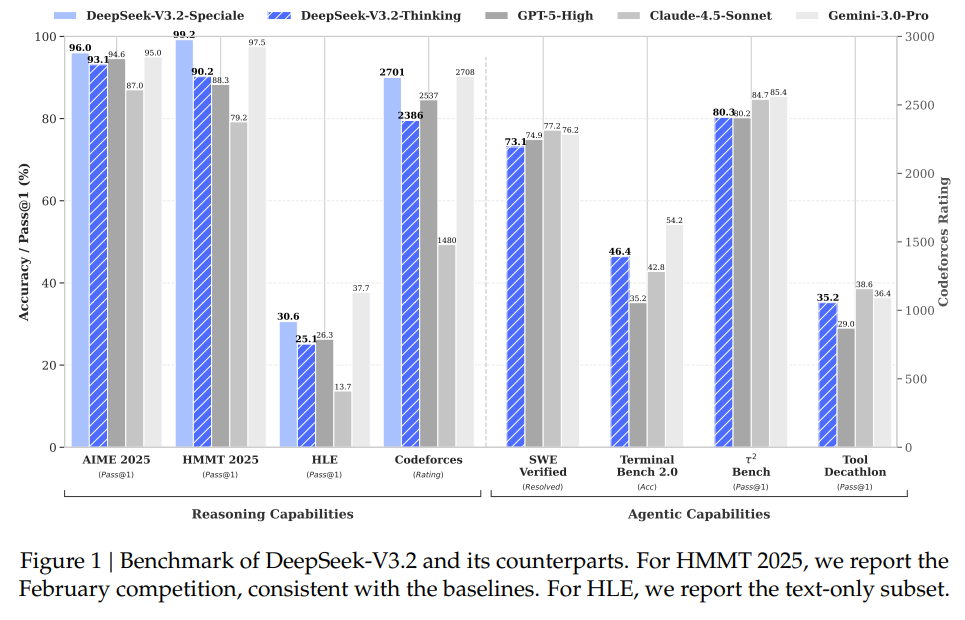
其 Thinking 工具支持边思考边调用工具,并利用“难解答、易验证”的数据任务,提升了编程和工具调用类任务的能力。从比较结果看,其推理和工具能力略高于 GPT-5,略低于 Gemini Pro 3.0 和 Claude Sonnet,全面高于国内其他模型。此外,V3.2 支持 Claude Code,让国内用户也可以使用 Claude Code。
1 技术突破
主要技术突破包含以下三个方面:分别解决了长上下文的效率问题;开源模型在具体任务上不如闭源模型的问题;以及 Agent 调用工具解决具体问题的能力。
1.1 DSA:稀疏注意力
DSA 是相对前一版本(V3.1)在架构上的主要改进。其设计初衷是:在生成长文本时,模型不必在每个 token 之间都计算完整的注意力,而只需关注与当前内容最相关的部分。DSA 包含两个核心部分:LightningIndexer 和 细粒度的 token 选择器。
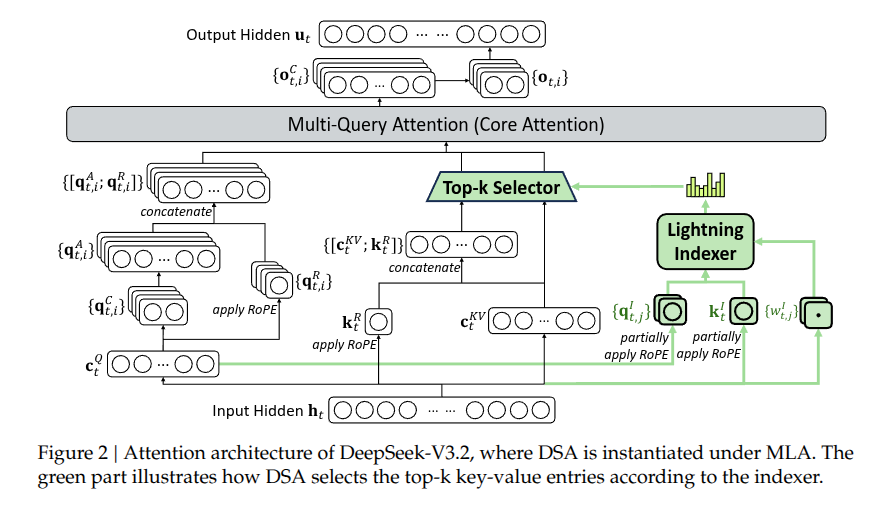
LightningIndexer 用于快速扫描前面所有的词,为每个词计算一个“重要性分数”。它设计得非常轻量高效(使用了 FP8 低精度计算),像一个快速的筛选器,决定哪些词值得进一步关注。细粒度 token 选择 的工作过程是:索引器为所有前面的词打分,只选出分数最高的前 k 个词(比如 top-32),然后只对这些选中的词进行完整的注意力计算。
为了避免相互干扰,DSA 的索引机制与主模型的注意力机制在功能上是解耦的,并通过持续训练的方式集成到模型中。这样做的好处是大幅加速了长文本的处理效率,同时不明显损失效果;由于排除了大量无关信息的干扰,模型效果甚至可能变得更好。
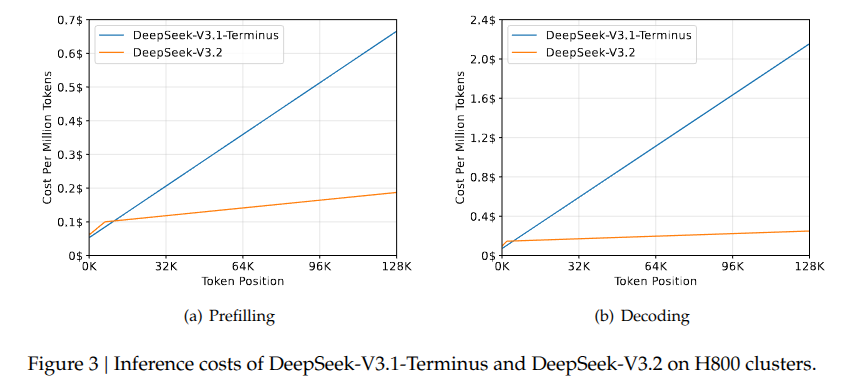
从图 -3 可以看出,采用这个方法后,推理成本也显著降低:
1.2 可扩展的强化学习
训练从一个预先训练好的 DeepSeek-V3.2 基础检查点开始。除了写作任务和一般问答外,强化学习框架还涵盖了六个专业领域:数学、编程、一般逻辑推理、通用智能任务、智能体编码和智能搜索,所有领域都支持思考模式和非思考模式。
该方法仍然采用群体相对策略优化GRPO作为强化学习训练算法。在 DeepSeek-V3.2-Exp 版本中,团队将推理、智能体和对齐训练合并为一个统一的强化学习阶段。
尽管在核心算法上没有提出全新的方法,但本工作的重点在于展示如何通过超大规模、高质量、多领域定向的 GRPO 后训练,来全面且均衡地提升模型在各种核心任务上的最终性能。最终,在普通对话中,其效果接近 ChatGPT-5;在推理问题上,DeepSeek-V3.2-Speciale 超越了 GPT-5,并在推理能力上与 Gemini-3.0-Pro 相当。
1.3 把推理融入工具使用的场景
之前的 DeepSeek-R1 策略——在第二轮消息到达时丢弃推理痕迹——会导致显著的令牌效率低下。这种方法迫使模型在每次后续工具调用时,都对整个问题进行冗余的重新推理。为了缓解这一问题,团队开发了专门针对工具调用场景定制的上下文管理机制。只在开启全新任务时移除之前的推理过程,当推理痕迹被移除时,工具调用的历史及其结果依然保留在上下文中。
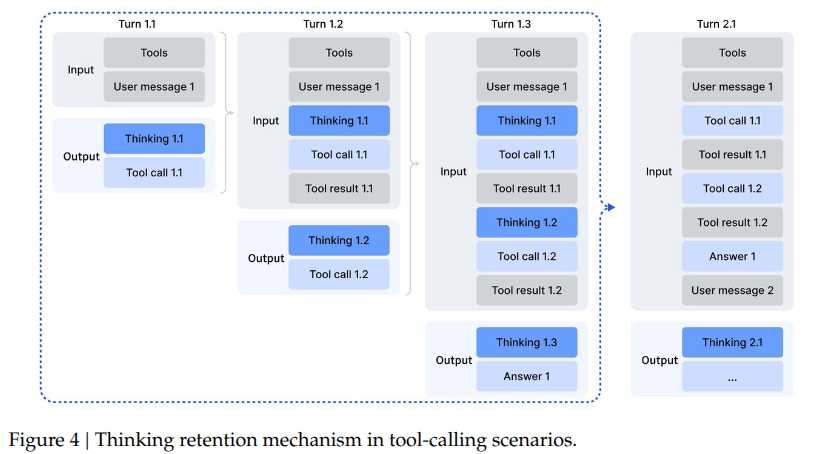
这里针对不同类型的任务,设计了不同的数据生成与优化方法。这些庞大的合成数据驱动了强化学习过程,显著提升了模型在智能体环境中的泛化能力和指令遵循能力。
以通用任务为例,为了在强化学习中扩展智能体环境和任务,需要构建那些难以解决(可能性很多)但易于验证的题目。出题过程是一个让 AI 自主进行“出题 - 解题 - 验证 - 升级难度 - 补充工具”的闭环迭代过程,目标是批量制造高质量、可自动评测的复杂任务。
按照这一工作流程,获得了数千个 <环境, 工具, 任务, 验证器> 元组。然后使用
DeepSeek-V3.2
对该数据集进行强化学习,只保留 pass@100 > 0 的实例(即模型尝试解决
100 次,至少成功一次的任务),最终得到了 1,827
个高质量的环境及其对应任务。